Due to the size and volume of unstructured textual data, automatic processing techniques are desired by many researchers in business and economic studies. A common use case is the data scraped from Internet. Researchers can process it using the algorithm called named entity linking. It finds concepts in texts (e.g., organisations, persons and locations) and links these concepts to entities in a knowledge base.
UB Mannheim developed the pipeline spaCyOpenTapioca for named entity linking in spaCy using OpenTapioca. It has low computational requirements and links the concepts to entities in Wikidata. The open source code is available at GitHub. It is supplemented with Jupyter Notebook and reproducible Binder.
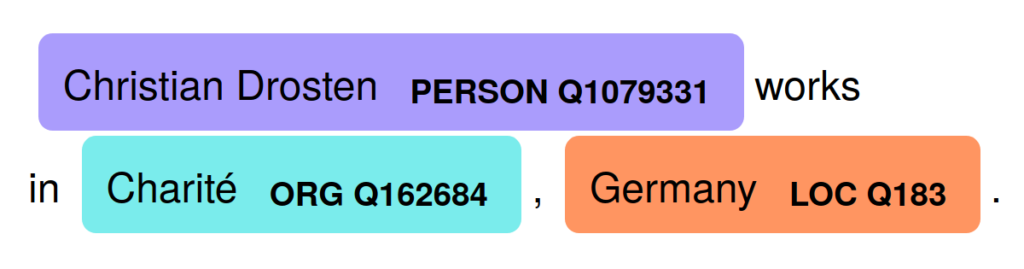
Let’s apply spaCyOpenTapioca to the sentence “Christian Drosten works in Charité, Germany.”. It correctly identifies Christian Drosten as a person with Wikidata ID Q1079331, Charité as organisation with Q162684 and Germany as location with Q183. Visualisation of results is also possible: